What are the Top 6 Machine Learning Algorithms You Should Know for 2023?
-

Pratik Roy

For the past several years, our understanding of the most essential machine learning algorithms has been informed by our professional experience, discussions with other data scientists, and research conducted online.

This year, we hope to build upon the content from last year by offering an extensive selection of models across several categories. Our aim is to create a comprehensive resource of data science methods and techniques that you can easily refer to whenever you face a problem.
In this article, we will explore six of the most essential machine learning algorithms. So, let’s get started!
1. Explanatory Algorithms
One of the biggest challenges with machine learning is deciphering how different models arrive at their end results. We are often aware of the “what”, but lack the understanding of the “why”.
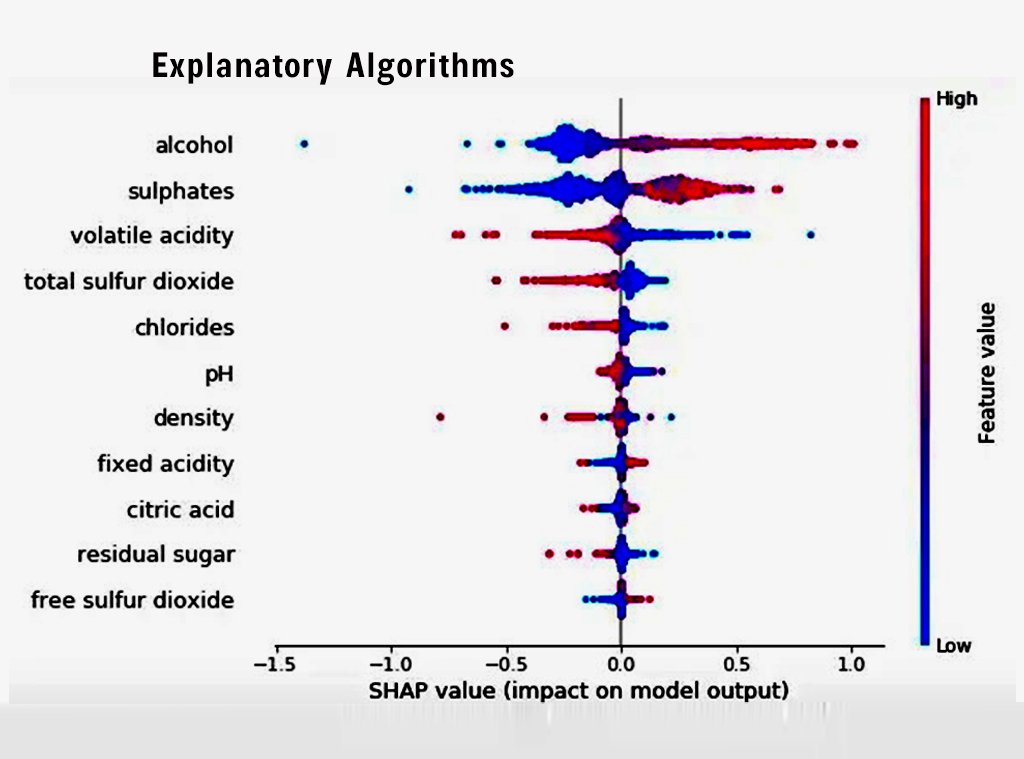
Explanatory algorithms enable us to discover the factors that have a significant effect on the result we are aiming to achieve. These algorithms allow us to comprehend the connections between the variables in the model, instead of just using the model to anticipate the outcome.
There are various methods that can be utilized to analyze the correlation between the independent variables and the dependent variable in a given model.
Algorithms
Linear/Logistic Regression : is a statistical tool that can be used to investigate the linear associations between a dependent variable and one or more independent variables. This technique can be used to assess the connections between factors based on the t-tests and coefficients.
Decision Trees : are a type of Machine Learning algorithm that creates a tree-like model of decisions and the potential outcomes associated with them. This is useful for understanding the relationship between different variables by examining the criteria that separate each branch of the tree.
Principal Component Analysis (PCA) : is a method of reducing the number of features in a dataset while still preserving as much of the variance in the data as possible. It is used to simplify the data and to identify the most important features in the dataset.
LIME : is an algorithm which provides explanations for the predictions of any machine learning model by constructing a simpler model in the vicinity of the prediction point. This simpler model can be constructed using approaches like linear regression or decision trees.
Shapley Additive explanations (SHAPLEY): is an algorithm that provides explanations for the predictions of any machine learning model by calculating the contribution of each feature to the prediction using a technique based on the idea of “marginal contribution.” In certain cases, it can be more precise than SHAP.
SHAP (Shapley Approximation) : is a method of attributing the prediction of any machine learning model to individual features. It uses a technique called “coalitional game” to approximate the Shapley values and is generally more efficient than the traditional Shapley approach.
2. Pattern Mining Algorithms
Pattern mining algorithms are a type of data mining technique employed to recognize patterns and associations within a dataset. These algorithms can be applied for various purposes, for example discovering customer purchasing patterns in a retail setting, recognizing common user behaviour sequences for a website/app, or uncovering relationships between different variables in a scientific study.
Pattern mining algorithms are used to analyze large datasets and search for repeated patterns or correlations between variables. These patterns can then be used to make predictions about future events or outcomes, or to gain insight into the relationships within the data.
Algorithms
Apriori : is an algorithm for discovering frequent item sets in a transactional database which is popular for mining association rules. It is also known for its efficiency.
A Recurrent Neural Network (RNN) : is a type of neural network that is designed to work with sequential data by taking into account temporal dependencies in the data.
Long Short-Term Memory (LSTM): is a type of recurrent neural network designed to store information for extended durations. It has the capacity to retain relationships in the data and is often utilized for activities like language translation and sentence production.
SPADE (Sequential Pattern Discovery Using Equivalence Class) : is an efficient method for finding frequent patterns in large datasets by grouping together items that are equivalent in some sense. However, it may not be suitable for use with sparse data.
PrefixSpan :is an algorithm for discovering frequent patterns in sequential data. It does this by creating a prefix tree and eliminating infrequent items. PrefixSpan can handle large datasets with efficiency, but may not be as effective when dealing with sparse data.
3. Ensemble Learning
Ensemble algorithms are powerful machine learning techniques that combine the predictions from multiple models to generate more accurate results than any of the individual models alone. This is achieved by leveraging the strengths of multiple models to compensate for the weaknesses of any single model, thus improving overall performance.

Diversity: By combining the predictions of multiple models, ensemble algorithms can capture a wider range of patterns within the data.
Robustness: Ensemble algorithms are generally less sensitive to noise and outliers in the data, which can lead to more stable and reliable predictions.
Reducing overfitting: By averaging the predictions of multiple models, ensemble algorithms can reduce the tendency of individual models to overfit the training data, which can lead to improved generalization to new data.
Improved accuracy: Ensemble algorithms have been shown to consistently outperform traditional machine learning algorithms in a variety of contexts.
Algorithms
Random Forest: a machine learning algorithm that creates an ensemble of decision trees and makes predictions based on the majority vote of the trees.
XGBoost: a type of gradient boosting algorithm that uses decision trees as its base model and is known to be one of the strongest ML algorithms for predictions.
LightGBM: another type of gradient boosting algorithm that is designed to be faster and more efficient than other boosting algorithms.
CatBoost: A type of gradient boosting algorithm that is specifically designed to handle categorical variables well.
4. Clustering
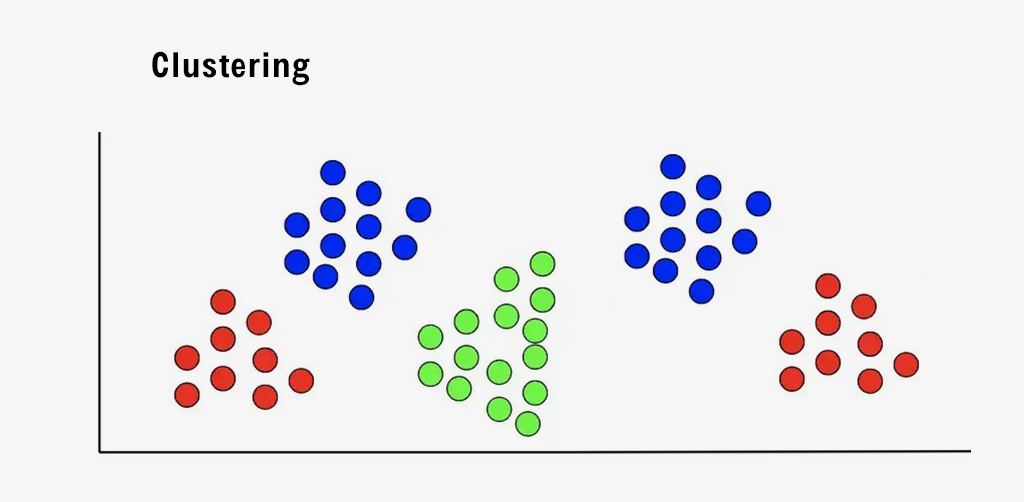
Clustering algorithms are a type of unsupervised machine learning that is used to classify data into distinct groups or “clusters” without any prior knowledge of the target variable.
This technique is useful for uncovering natural patterns and trends in data, as well as for dividing a dataset into segments based on various variables. It is often used during exploratory data analysis to gain a deeper understanding of the data. One popular application of this is in segmenting customers or users.
Algorithm
K-mode clustering : is a type of clustering algorithm designed to identify clusters within categorical data. It is effective at analyzing high-dimensional datasets and straightforward to implement.
DBSCAN: A density-based clustering algorithm that is able to identify clusters of arbitrary shape. It is relatively robust to noise and can identify outliers in the data.
Spectral clustering: is an efficient clustering algorithm that uses the eigenvectors of a similarity matrix to group data points into clusters. This method is particularly useful for dealing with non-linearly separable data.
5. Time Series Algorithms
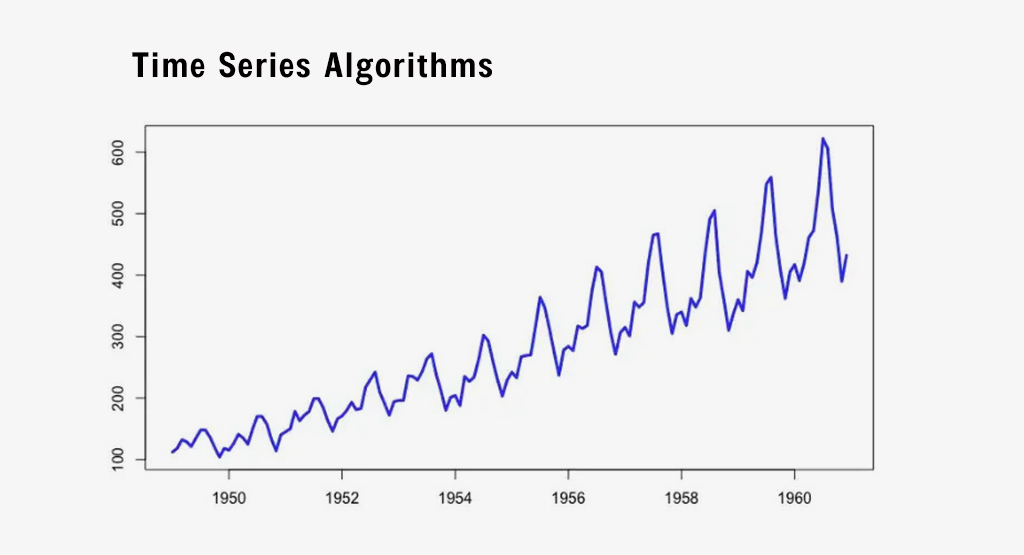
Time series algorithms are methods utilized to examine data with a time-dependent nature. These algorithms factor in the time-based connections between data points in the series, which is particularly vital when attempting to make forecasts about potential values.
Alogrithm
Prophet time series modelling: A time series forecasting algorithm developed by Facebook that is designed to be intuitive and easy to use. Some of its key strengths include handling missing data and trend changes, being robust to outliers, and being fast to fit.
Autoregressive Integrated Moving Average (ARIMA): A statistical method for forecasting time series data that models the correlation between the data and its lagged values. ARIMA can handle a wide range of time series data but can be more difficult to implement than some other methods.
Exponential smoothing: Exponential smoothing is a technique for predicting time series data, which leverages a weighted average of previous data points to make forecasts. While this method is relatively easy to put into practice and is compatible with diverse types of data, it may not deliver as strong a performance as more advanced methods.
6. Similarity Algorithms
Similarity algorithms are employed to evaluate similarity between pairs of records, nodes, data points, or text. These algorithms can be based on the distance between two data points (e.g. Euclidean distance) or on the similarity of text (e.g. Levenshtein Algorithm).
These algorithms have a wide range of applications, but are particularly useful in the context of recommendations. They can be used to identify similar items or suggest related content to users.
Algorithms
Euclidean Distance: Euclidean distance is a straightforward way to calculate the direct distance between two points in Euclidean space, and is commonly used in machine learning. However, it may not be the most suitable option when dealing with data that is unevenly distributed.
Cosine Similarity: a measure of similarity between two vectors based on the angle between them.
Levenshtein Algorithm: The Levenshtein algorithm is a method for calculating the distance between two strings by determining the minimum number of individual character operations such as deletions, insertions, or substitutions needed to transform one string into the other. This algorithm is frequently utilized in tasks like string matching and spell-checking.
Jaro-Winkler Algorithm: The Jaro-Winkler algorithm is a technique for evaluating the similarity between two strings by considering the count of identical characters and the number of character transpositions. This algorithm, similar to the Levenshtein algorithm, is frequently employed in record linkage and entity resolution tasks.
Singular Value Decomposition (SVD): Matrix factorization is a mathematical technique that breaks down a matrix into three separate matrices, and it plays a vital role in cutting-edge recommendation systems.
Related Articles
-
 Various Applications of AI-powered Customer Contact Centers Across Industries
Various Applications of AI-powered Customer Contact Centers Across IndustriesIn today’s fast-paced digital world, businesses increasingly use artificial intelligence (AI) to revolutionize customer contact centers. AI applications are reshaping the customer service landscape, enhancing operational efficiency and the customer
-
How Artificial Intelligence Trading Technology is Educating Stock Market Investors?
Have you seen the equations that experienced traders make in their heads? Or have you seen how recent trades are being recorded while current data is being monitored in movies?
-
 Top Generative AI Content Writing Tools for 2026
Top Generative AI Content Writing Tools for 2026Generative AI tools are transforming content creation across multiple industries by offering innovative solutions that enhance productivity and creativity. These tools assist marketers, writers, and businesses in producing high-quality content