Secrets to Stable Training for Large-Scale Generative Models
-

Pratik Roy

Artificial Intelligence (AI) is no longer just a futuristic concept; it’s the backbone of modern business innovation. Generative models are revolutionizing industries by enhancing chatbots with large language models (LLMs). Generative Adversarial Networks (GANs) also produce hyper-realistic images that impact product design and customer experiences.
But building these powerful models isn’t easy or cheap. One misstep in training can lead to “training instability,” the AI equivalent of constructing a skyscraper that wobbles mid-build. It is costly, time-consuming, and risky.
This guide dives into why training stability matters, how instability can impact your bottom line, and the proven techniques, like Gradient Clipping and Spectral Normalization, that safeguard your AI investments and ensure your models reach their full potential.
The Generative Model Landscape: A Tale of 3 Architectures

To understand stability, know what you’re stabilizing. Generative models learn data patterns to create authentic new data. The three most common architectures are:
01 | Generative Adversarial Networks (GANs): The AI Showdown
How They Work (Simplified): GANs are a face-off between two neural networks:
- The Generator: The “artist” that tries to create realistic fake data (e.g., a fake face).
- The Discriminator: The “critic” that tries to tell the fake data from the real data.
They train in an adversarial (competitive) game. The Generator gets better at fooling the critic, and the critic gets better at catching the fakes. The result? Stunningly realistic outputs.
The Stability Challenge: That competitive dynamic is a double-edged sword. If the critic gets too good too fast, the artist gives up (vanishing gradients). If the artist gets stuck on a few good outputs, it keeps repeating them (mode collapse). Training Generative Adversarial Networks (GANs) tends to be exceptionally unpredictable.
Diffusion models offer a more reliable training process than GANs, effectively avoiding the issue of mode collapse. This stability arises from their structured framework, which systematically learns to reverse a diffusion process that transitions data from a simple prior distribution to the complex distribution of the target data.
Read More-: Generative Models Unpacked: The Innovations Powering Next-Gen AI
02 | Variational Autoencoders (VAEs): The Statistical Approach
How They Work: VAEs are less about competition and more about learning an efficient, compressed “blueprint” of the data, called a latent space. The model then generates new data by sampling from this blueprint.
The Stability Challenge: VAEs are much more stable than GANs but often struggle to produce high-fidelity (sharp, clear) outputs. Their primary failure, known as “posterior collapse,” occurs when the model defaults to a simple, uninformative output, ignoring the complex blueprint.

03 | Large Language Models (LLMs) and Diffusion Models: The New Gold Standard
How They Work:
- LLMs are large models that predict the next word in a sequence using extensive text data.
- Diffusion Models add noise to an image until it becomes static, then learn to reverse that process step-by-step to recreate a perfect image.
The Stability Challenge: While generally more stable than classic GANs, their large size means small instabilities, like “exploding gradients,” which can cause major failures and waste significant computing time. The cost of restarting a failed training run for a large model can be staggering.
Understanding the Instability Crisis: What Goes Wrong?

Training a neural network involves making minor, corrective adjustments to its internal parameters (weights) based on the “gradient”, the direction and size of the error. Think of it as a mountain climber finding the fastest way down (the minimum error, or loss).
The two main failures of stability are related to the gradient:
01 | Exploding Gradients (The Oversized Step)
The Problem: In deep networks (like those in LLMs and GANs), the gradient calculation involves multiplying small numbers through many layers. Sometimes, this multiplicative effect suddenly causes the gradient to become enormously large; we call this an “exploding gradient.”
The Business Impact: If the mountain climber takes one giant, uncontrolled leap, they’ll overshoot the minimum, land somewhere chaotic, or even fly off the mountain entirely. This important update dramatically changes the model’s weights, undermining the learning process. The model becomes unstable, and its output becomes garbage. You have to stop training and start over.
02 | Vanishing Gradients (The Lost Snail)
The Problem: The opposite effect is the “vanishing gradient,” where the gradient becomes so incredibly small that it’s almost zero.
The Business Impact: The climber is moving so slowly that it’s barely moving. The front layers of the network stop learning. The model’s progress stalls, its loss plateaus, wasting time and resources without meaningful improvement.
Read More-: Self-Supervised Learning: The Secret Sauce Behind Smarter Generative AI
The Business Cost of Instability: Time is Money

Training a large-scale generative model is a heavy financial commitment. Instability directly translates to severe financial and strategic setbacks.
According to a 2024 analysis by Epoch AI, the cost of training frontier AI models has been increasing by 2 to 3x per year over the past 8 years. This exponential growth suggests that in 2027, the price tag for training the largest AI models could exceed $1 billion.
Every time you restart a model’s training due to divergence, you lose valuable progress.
- Cloud Computing/Hardware Costs: Paying for specialized chips (like GPUs or TPUs) that sat idle or produced a useless result.
- Engineering Time: Highly paid AI engineers who must debug the failure, adjust the hyperparameters, and re-launch the process.
- Time-to-Market: Delays in launching your innovative AI product give competitors a critical advantage.
Stabilizing training is not just sound engineering; it is essential financial management.
Core Techniques for Stability: The AI Safety Net

AI practitioners employ powerful and indispensable techniques to mitigate the two main risks of instability, exploding and vanishing gradients. For our business audience, we’ll focus on two of the most effective and widely used techniques: Gradient Clipping and Spectral Normalization.
01 | Gradient Clipping: The Speed Limit for Learning
Gradient Clipping is like a speed limit for training a machine learning model. It helps keep the model’s weight changes safe and stable.
How It Works:
- The gradient shows how much to change the model, similar to a car’s speedometer.
- You set a speed limit (clip threshold):
- The model trains as usual if the gradient is under the limit.
- If it exceeds the limit, Gradient Clipping reduces the gradient to meet the speed limit.
Benefit: This technique prevents issues like exploding gradients, especially in complex models like Recurrent Neural Networks (RNNs) and large language models (LLMs), ensuring stable and predictable training.
02 | Spectral Normalization: Taming the Generator’s Wildness
Spectral Normalization is a key method for stabilizing GANs and other deep learning models. It prevents the model from getting stuck in non-converging cycles and stops the Generator from becoming too powerful too quickly, ensuring smooth training.
How it Works: Consider a neural network as a musical instrument. As it learns, its “sound” (parameters) can become messy, leading to poor results. Spectral Normalization acts like a tuner, limiting how much “volume” or “energy” each layer can use. Regulating how quickly the output responds to the input ensures that everything remains smooth and predictable.
Technical Simplicity: Spectral Normalization controls the Lipschitz constant to stabilize neural networks. To improve evaluation and prevent “mode collapse,” we must stop the generator from producing unpredictable outputs.
Business Benefit: Improved stability and learning for GANs produce more diverse, high-quality results with fewer repeated patterns.
The Path to Seamless Training
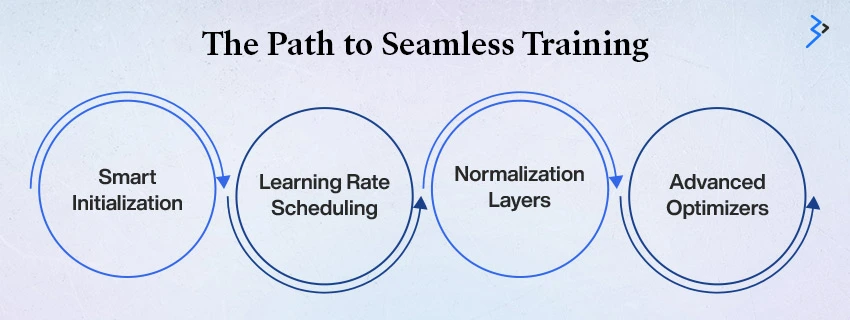
Beyond the two core techniques, a successful AI strategy incorporates stability at every stage:
A. Smart Initialization (The Head Start)
The starting values of the model’s weights matter immensely. Clever initialization schemes like Xavier and Kaiming ensure well-behaved gradients, preventing vanishing or exploding issues.
B. Learning Rate Scheduling (The Smart Pacer)
The learning rate controls how a model updates its weights. Scheduling starts high for rapid learning and decreases for fine-tuning, enabling the model to find the best solution.
C. Normalization Layers (Standardizing the Process)
Techniques like Batch Normalization or Layer Normalization standardize the inputs to each network layer. Imagine every layer getting data within a perfect, predictable range. It is essential to avoid internal shifting and scaling problems, as they can quickly destabilize deep networks.
D. Advanced Optimizers (The Master Navigator)
Many practitioners commonly use optimizers like Adam or RMSprop, but they may need to employ more advanced optimizers for generative ai models. These tools dynamically adjust the learning process, essential for navigating generative AI’s complex error landscapes.
Conclusion: Securing Your AI Future with Stability
The rise of generative AI presents exciting opportunities and challenges, such as high costs and instability risks. For companies investing heavily in AI, ensuring stable training is crucial for success and maximizing returns.
Techniques like Gradient Clipping and Spectral Normalization can help make AI development more reliable. This focus on stability leads to better resource use, keeps teams productive, and ensures timely product launches.
A stable approach is essential for succeeding with generative AI app development projects and achieving high-quality results. Brainvire offers expert AI engineering to support a smooth transition from raw data to market-ready models.
FAQs
Training stability helps AI models learn consistently, making them efficient and reliable. Minimizing restarts and reducing wasted resources achieves quicker training, improved outcomes, and cost savings.
Instability during training can occur due to issues like extreme gradients, poor weight initialization, or an imbalance between the Generator and Discriminator in GANs. These problems can disrupt training, leading to poor results and increased costs.
Training stability ensures an AI model learns reliably, working faster and better, which saves businesses time and money by reducing restarts.
Training stability helps an AI model learn smoothly and reliably, leading to better results and faster training. Also saves businesses time and money by reducing the need for restarts and wasted resources.
Training stability allows AI models to learn consistently, making them faster and more reliable, which saves businesses time and money.
Related Articles
-
 Chatbots and Their Impact on Customer Support
Chatbots and Their Impact on Customer SupportIntroduction In today’s digital age, where customer expectations are sky-high, businesses constantly seek innovative ways to enhance customer experience (CX). Enter chatbots – virtual assistants that are revolutionizing the customer
-
 LaMDA: The next big thing in conversational AIs
LaMDA: The next big thing in conversational AIsGoogle search is, without a doubt, the most straightforward way to find answers to our everyday questions. It’s so commonplace that it’s become second nature to us all. It provides
-
Leveraging the Power of Artificial Intelligence in Cybersecurity
The rise in cybercrime and the need to invest heavily in cybersecurity has led to concerns that companies may become more vulnerable to cyberattacks as they adopt AI and machine learning in their operations. However, AI and machine learning have potential in cybersecurity responses to combat advanced cyber threats. The use of these technologies may enable companies to react to and prevent attacks in more sophisticated ways.