Top Data Pipeline Best Practices for Building Robust Pipelines
-

Pratik Roy
Data is the lifeblood of every profitable company decision in the modern digital age. From powering dashboards and predictive analytics to training machine learning models and supporting real-time actions, organizations depend on fast, scalable, and reliable access to data. That’s where data pipelines come in.
These behind-the-scenes workhorses quietly move data from various sources, transform it into usable formats, and deliver it to the right systems—accurately and on time. But while they may seem invisible, their impact is massive. Poorly designed pipelines can lead to inconsistent data, processing delays, and costly inefficiencies.
To truly harness the power of your data, you need pipelines that are not only fast and scalable but also resilient and easy to maintain. In this guide, we’ll walk you through the top best practices for building strong, streamlined data pipelines that can grow with your business and stand the test of time.
What Is a Data Pipeline?
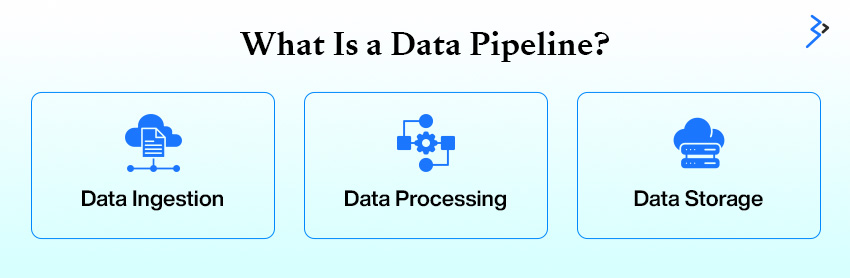
A data pipeline is a set of processes transporting data from various sources to destinations, typically databases, data warehouses, or data lakes. Data might undergo transformations, validations, aggregations, and enrichments along the way.
There are typically three main components:
- Data Ingestion: Collecting raw data from multiple sources.
- Data Processing: Cleaning, transforming, and enriching the data.
- Data Storage: Loading the data into a destination system where applications can analyze or consume it.
Whether the pipeline is batch-based or real-time (streaming), reliability, consistency, and scalability are critical for success.
Why Do Data Pipelines Matter?
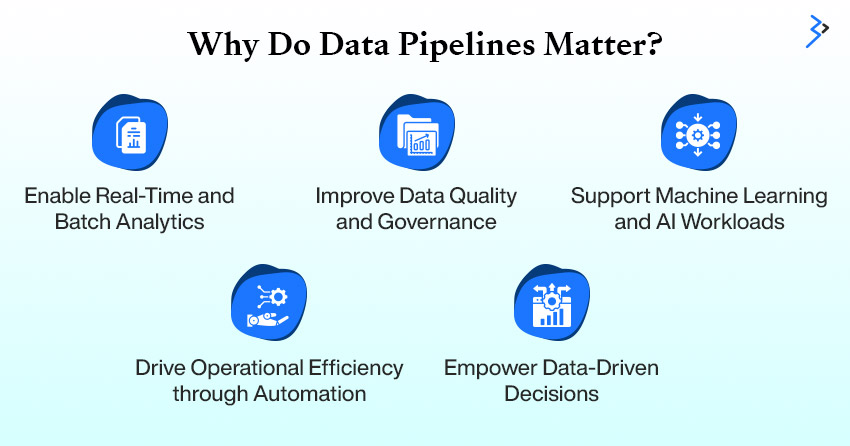
Nowadays, businesses thrive on real-time insights and rapid decision-making. Data pipelines—the systems responsible for collecting, transforming, and delivering data across an organization are at the heart of this digital transformation. Without them, data would remain siloed, inconsistent, or outdated. Here’s why they matter more than ever:
- Enable Real-Time and Batch Analytics: Data pipelines support both streaming (real-time) and batch processing, allowing businesses to respond instantly or analyze large volumes of historical data, depending on the use case.
- Improve Data Quality and Governance: Pipelines ensure that only high-quality, reliable data flows into your systems through automated validations, cleansing, and formatting. This also helps maintain compliance with data regulations like GDPR and HIPAA.
- Support Machine Learning and AI Workloads: Clean, well-structured data is essential for training ML and deep learning models. Pipelines automate the delivery of consistent datasets to fuel everything from recommendation engines to predictive analytics.

- Drive Operational Efficiency through Automation: Pipelines reduce manual effort and streamline workflows by automating repetitive and error-prone tasks such as data ingestion, transformation, and delivery.
- Empower Data-Driven Decisions: Reliable data pipelines ensure stakeholders have access to real-time and accurate information, enabling smarter, faster decisions across departments.
From financial institutions analyzing shifting market trends in real time to eCommerce platforms recommending products based on user behavior, robust data pipelines are critical to modern innovation. They’re not just infrastructure but strategic assets driving growth, efficiency, and competitiveness in this digital economy.
Building resilient, scalable, and intelligent data pipelines is the first step in future-proofing your organization.
Top Data Pipeline Best Practices
Let’s dive into the best practices to design, build, and maintain high-performing data pipelines.
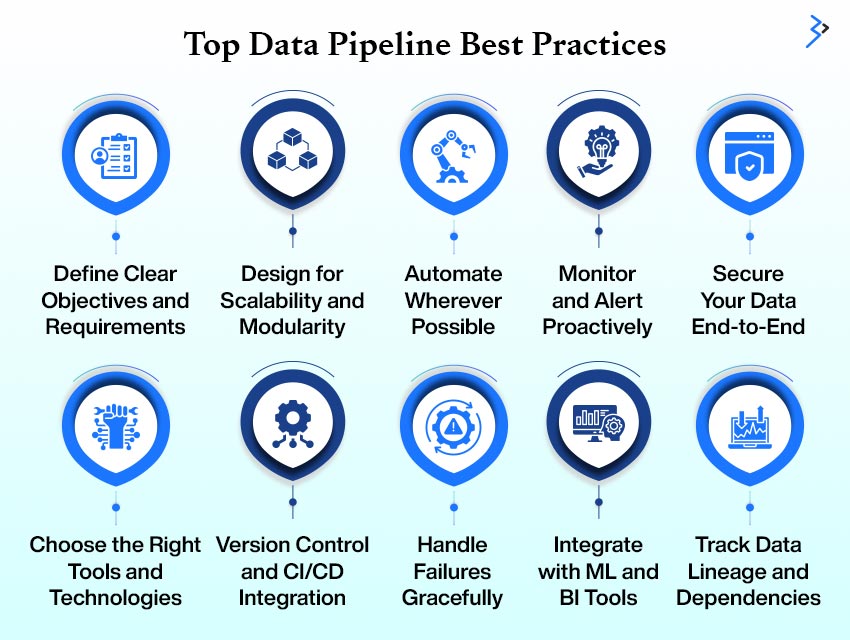
1. Define Clear Objectives and Requirements
Before implementing, understand the data pipeline’s end goals. Is it for real-time analytics? Are you preparing data for a data lake? What are the latency, accuracy, and availability requirements?
Best Practice Tips:
- Identify business objectives and KPIs.
- Map data sources and define data consumers.
- Document SLAs and latency thresholds.
Having a clear understanding ensures you build with purpose, not guesswork.
2. Design for Scalability and Modularity
Pipelines should grow with your data. A scalable architecture prevents bottlenecks as data volume, variety, and velocity increase.
Best Practice Tips:
- Break pipelines into modular stages (ingestion, validation, transformation).
- Use scalable tools like Apache Kafka, Spark, or cloud services.
- Opt for containerization (Docker, Kubernetes) to ensure elastic compute.
Designing with modularity allows you to update or fix components without affecting the entire pipeline.
3. Automate Wherever Possible
Manual interventions introduce inconsistency. Automation brings speed, repeatability, and reduced risk.
Best Practice Tips:
- Automate data ingestion, transformation, and deployment steps.
- Use workflow orchestration tools like Apache Airflow or AWS Step Functions.
- Integrate automated alerts and failure recovery mechanisms.
The less you depend on human intervention, the more resilient your pipelines become.
4. Implement Strong Data Governance and Quality Checks
It’s harder than it looks to get this right from the start, which is why many businesses hire data governance consulting firms to build the systems that keep data safe as pipelines grow.
No matter how well-structured your pipeline is, poor-quality data leads to poor decisions.
To further enhance the reliability of customer data, companies can integrate an International address verification API to validate and standardize addresses as they flow through the pipeline.
Best Practice Tips:
- Validate schema conformity at each stage.
- Perform anomaly detection using rules or machine learning.
- Maintain metadata and lineage tracking using tools like Apache Atlas.
Data quality metrics like completeness, accuracy, timeliness, and consistency should be monitored regularly.
5. Monitor and Alert Proactively
You can’t improve what you don’t measure. Real-time monitoring ensures your pipelines are functioning as intended.
Best Practice Tips:
- Use observability tools (Prometheus, Grafana, Middleware, Datadog).
- Monitor data volumes, latencies, and error rates.
- Set up alerts for anomalies, failures, or performance dips.
Proactive monitoring prevents business disruptions and helps maintain trust in your data infrastructure.
6. Secure Your Data End-to-End
With increasing regulations like GDPR, HIPAA, and CCPA, securing data in transit and at rest is non-negotiable.
Best Practice Tips:
- Encrypt data during transit (SSL/TLS) and at rest (AES-256).
- Use identity-based access controls and audit trails.
- Regularly patch and update pipeline components.
Security should be baked into the design, not an afterthought.
7. Choose the Right Tools and Technologies
Not all pipelines are the same. The right tool stack depends on your use case, scale, and team expertise. For pipelines that gather web-based search data, using Google proxies and california proxies allows teams to access unbiased, localized search results from multiple regions, ensuring reliable input for analytics and machine learning workflows.
Popular Tools by Stage:
- Ingestion: Apache NiFi, Kafka, Fivetran, AWS Kinesis
- Processing: Apache Spark, dbt, Flink, Azure Data Factory
- Storage: Snowflake, Redshift, Google BigQuery, Data Lakes
- Orchestration: Airflow, Prefect, Dagster
Stay vendor-agnostic if possible to avoid lock-in.
8. Optimize for Performance
Efficient pipelines save costs and reduce processing delays. Optimization ensures your system isn’t overburdened.
Best Practice Tips:
- Avoid excessive data shuffling and unnecessary joins.
- Partition data intelligently for parallel processing.
- Use caching and indexing for repeated queries.
Remember, performance tuning should be iterative and data-driven.
9. Version Control and CI/CD Integration
Modern data engineering embraces the DevOps philosophy. Pipelines should be treated like code.
Best Practice Tips:
- Use Git to version pipeline definitions and configurations.
- Implement CI/CD pipelines for testing and deployment.
- Use environment separation (dev, staging, prod).
This improves collaboration, traceability, and rollback capabilities.
10. Handle Failures Gracefully
Failures like network issues, schema changes, and service outages will happen. The key is graceful degradation and automatic recovery.
Best Practice Tips:
- Implement retries with exponential backoff.
- Use idempotent operations to avoid duplicates.
- Build dead-letter queues for failed records.
Resiliency ensures data pipelines can recover with minimal human effort.
11. Document Everything
A well-documented pipeline saves hours during debugging, onboarding, or scaling.
Best Practice Tips:
- Maintain architectural diagrams and data flow charts.
- Document dependencies, configs, and schema mappings.
- Keep a changelog of updates and fixes.
Documentation is your single source of truth for transparency and collaboration.
12. Support Real-Time and Batch Workloads
While batch processing remains popular, many organizations need real-time insights for decision-making.
Best Practice Tips:
- Use message queues (Kafka, RabbitMQ) for real-time ingestion.
- Architect hybrid pipelines that support both batch and stream processing.
- Manage latency trade-offs according to business needs.
Flexibility is key to addressing diverse data needs across teams.
13. Integrate with ML and BI Tools
Data pipelines are not just for storage—they power machine learning development, dashboards, and automated reports.
Best Practice Tips:
- Use pipelines to feed training data into ML models.
- Automate updates to BI dashboards as new data arrives.
- Connect data lakes and warehouses with analytics tools like Tableau, Power BI, or Looker.
Pipelines must be analytics-ready for full data value extraction.
14. Track Data Lineage and Dependencies
Data lineage helps you understand where your data came from and how it changed over time.
Best Practice Tips:
- Use lineage tools to trace column-level transformations.
- Understand upstream/downstream dependencies to manage changes.
- Maintain audit logs and metadata stores.
Lineage boosts data trustworthiness, compliance, and troubleshooting.
15. Foster Collaboration Between Teams
Data engineers, analysts, scientists, and business users must work in sync. Silos lead to misalignment and inefficiency.
Best Practice Tips:
- Use shared dashboards and centralized documentation.
- Hold regular pipeline review and data quality meetings.
- Align pipeline design with business priorities.
Cross-functional collaboration leads to better-designed, more useful pipelines.
Read More – Scaling Your eCommerce Business Effectively with Adobe Commerce on AACS
Real-World Use Cases of Robust Data Pipelines

In this data-driven world, businesses must rely on robust data pipelines tools to collect, process, and analyze vast information streams quickly and reliably. Data pipelines are the backbone of modern digital operations—integrating various data sources, transforming data into usable formats, and ensuring timely delivery to downstream systems.
Below, we explore how various industries leverage robust data pipelines to drive real-time insights and decision-making.
eCommerce: Personalization and Operational Efficiency
The eCommerce industry thrives on personalization and seamless customer experience. Robust data pipelines enable retailers to capture and act on user behavior across channels.
Use Cases in eCommerce:
- Sync customer activity across platforms: Track behavior from web and mobile app development to build a unified customer profile.
- Real-time recommendation engines: Feed clickstream and purchase data into ML models to personalize shopping experiences.
- Automate sales and inventory reports: Streamline analytics by automating daily sales metrics and inventory forecasts.
Benefits for eCommerce:
- Improved customer retention through personalized experiences
- Faster decision-making with real-time dashboards
- Accurate demand forecasting to optimize inventory
Healthcare: Improving Patient Outcomes with Data
In healthcare, aggregating and analyzing clinical data can make the difference between reactive and proactive patient care. Data pipelines ensure that vast, fragmented health records are unified and usable.
Use Cases in Healthcare:
- EHR and lab system integration: Combine patient data from multiple sources into one coherent dataset.
- Data cleaning for analytics: Standardize formats and remove inconsistencies for reliable analysis.
- Enable AI-powered diagnostics: Feed curated data into machine learning models for predictive diagnostics and treatment planning.
Benefits for Healthcare:
- Enhanced care coordination across providers
- Accurate diagnostic support with AI and analytics
- Timely alerts for patient anomalies
Finance: Real-Time Decision Making and Fraud Prevention
Financial institutions depend on real-time data to detect threats, assess risk, and capitalize on opportunities. Robust data pipelines help maintain accuracy and speed in high-stakes environments.
Use Cases in Finance:
- Fraud detection: Continuously monitor transaction streams to identify anomalies or suspicious behavior.
- Market data aggregation: Collect data from multiple financial sources to inform trading strategies and risk management.
- Real-time dashboards: Provide decision-makers with up-to-the-minute analytics and alerts.
Benefits for Finance:
- Reduced fraud losses through real-time alerts
- More informed investment decisions
- Streamlined compliance with data traceability
Manufacturing: Enhancing Efficiency with Smart Analytics
Downtime is costly in manufacturing. Robust data pipelines can process data from machines and sensors to predict failures and streamline operations.
Use Cases in Manufacturing:
- IoT data monitoring: Capture data from factory sensors to track machine health and usage patterns.
- Predictive maintenance: Analyze trends to anticipate equipment breakdowns and reduce downtime.
- Efficiency analytics: Aggregate production line data to find bottlenecks and optimize workflows.
Benefits for Manufacturing:
- Lower maintenance costs through prediction
- Higher uptime and productivity
- Data-driven process improvements
Summary Table: Use Cases by Industry
| Industry | Key Data Pipeline Use Cases | Impact |
| eCommerce | Sync activity, recommend products, automate sales/inventory | Personalization, forecasting, and fast insights |
| Healthcare | Integrate EHR/labs, clean data, and AI diagnostics | Better care, accurate analytics |
| Finance | Fraud detection, market data feeds, and real-time dashboards | Risk reduction, informed trading |
| Manufacturing | Monitor IoT, predictive maintenance, and efficiency analytics | Downtime reduction, cost savings |
Common Pitfalls to Avoid
Building a data pipeline is complex; without proper planning, it can lead to unreliable systems. Here are common mistakes and how to avoid them:
- Validate early: Poor input data leads to flawed outcomes—validate schema and values upfront.
- Avoid overengineering: Focus on the MVP first. Add complexity only when needed.
- Plan for scale: Choose scalable technologies and design for future data growth.
- Test transformations: Bugs in logic can silently corrupt insights—test thoroughly.
- Ensure observability: Use logging, metrics, and alerts to track data quality and flow.
Read More – Why .NET Core is the Best Choice for Modern Application Development – Key Features & Benefits
Future of Data Pipelines: What’s Next?

The landscape of data engineering is evolving with innovations that reduce manual effort and increase agility. Here’s what’s shaping the future:
- AI-powered data engineering: Tools that auto-tune pipeline performance, detect anomalies, and self-heal.
- DataOps methodologies: Bringing DevOps principles—CI/CD, version control, testing—into the data workflow.
- Low-code/no-code platforms: Empower business users to build and maintain simple pipelines without deep coding knowledge.
- Event-driven architectures: Shift from batch to streaming data pipelines for faster, responsive systems.
- Metadata-first design: Automate governance, lineage tracking, and compliance through metadata-aware platforms.
Mastering Modern Data Pipeline Strategies
Building a robust, scalable, and efficient data pipeline isn’t just about moving data—it’s about ensuring that the right data reaches the correct destination in the proper format at the right time. Whether you’re supporting analytics, machine learning, or operational intelligence, following best practices will help reduce risks, increase agility, and maximize value from your data assets.
Robust pipelines are the lifeblood of data-first organizations. They automate workflows, enforce governance, optimize performance, and support both batch and stream processing.
Ready to strengthen your data infrastructure? Start by evaluating your current pipelines, implementing these best practices, and empowering your team to innovate confidently.
FAQs
A data pipeline is a process that moves data from one system to another, often transforming and enriching it. It ensures data is reliable, timely, and ready for analysis or use in reporting, machine learning, and real-time analytics applications.
A robust data pipeline typically includes data ingestion, transformation, validation, storage, and orchestration. It may also include monitoring, alerting, and version control to ensure stability and reliability over time.
They provide clean, structured, and up-to-date data critical for training and running machine learning and AI models. Without well-managed pipelines, data scientists would struggle with data quality and consistency.
Common challenges include data inconsistency, lack of validation, poor scalability, insufficient testing, and limited observability. If not addressed properly, these can lead to delays, data loss, and incorrect analytics.
Batch pipelines process large volumes of data at scheduled intervals, while real-time (or streaming) pipelines process data instantly as it’s generated. Each serves different business needs based on use case requirements.
By adopting scalable cloud-native tools, implementing DataOps practices, using AI-powered automation, and focusing on metadata-driven designs. This ensures your pipelines remain efficient and adaptable as data needs evolve.
Related Articles
-
 The Pros and Cons of Shopify: Retail Ecommerce Solution
The Pros and Cons of Shopify: Retail Ecommerce SolutionMany business owners wonder whether or not they should employ an ecommerce platform to help them sell digital their products. However, with so many choices on the market, it can
-
 From Cart Abandonment To Slow Load Times: Streamlining The E-commerce Experience
From Cart Abandonment To Slow Load Times: Streamlining The E-commerce ExperienceThe success of any eCommerce solution company depends on streamlining the ecommerce experience through a well-designed and user-friendly website in today’s competitive market. Various factors, including Cart Abandonment Solutions, Mobile
-
The Hidden Cost To Deal With Unexpected eCommerce Challenges
Businesses across different industries have transformed drastically over the past couple of years. With the covid acting as a catalyst to the transition, the world has witnessed extensive digitization, further


